
Report
💡 Active projects and challenges as of 18.11.2025 13:09.
Hide text CSV Data Package Print
Guardrails as Code
Urs - Interprimis
Im Zentrum dieser Challenge stehen Guardrails as Code: Regeln und Policies, die bislang in Textform verborgen bleiben, werden in maschinenlesbare Formate (YAML/Frontmatter) übersetzt und automatisch in Business-Artefakte (PDF, Slides, Scorecards) transformiert. Damit wird Governance sichtbar, überprüfbar und direkt nutzbar – für Technik und Business gleichermaßen.
👉 TextCortex steht optional als unterstützende Ressource zur Verfügung – z. B. für Textgenerierung, Übersetzungen, Zusammenfassungen, Tagging und API-Integration. Teams können TextCortex einsetzen, müssen es aber nicht. Mehr Infos über TextCortex:
https://swissai.dribdat.cc/project/30
👥 Kernkompetenzbereiche für Teams (3–5 Personen)
Business Know How
- Analyse von Prozessen & Anforderungen, Transfer in technische Lösungen
- Projektleitung und Change-Management
- Datenschutz (CH/EU), Datenkompetenz, Digital Literacy
- Kommunikation intern/extern, Stakeholder-Management
- Fähigkeit zur Ergebnispräsentation & Storytelling
- Kreativität und Innovationswille
- Usability/UX-Bewusstsein
- Flexibilität & schnelle Problemlösung im Team
Citizen Skills
- Offenheit für Low-/No-Code Tools & schnelle Prototypen
- Analytische und kritische Denkweise
- Bereitschaft zur Teamarbeit & konstruktiver Kommunikation
- Grundverständnis für Datenflüsse im Unternehmen
- Umsetzung und Präsentation eigener Ideen im Team
- Lernbereitschaft und Technologieaffinität
Entwickler Skills
- Python-Skripting für Datenextraktion, Parsing (PDF, Web)
- Entwicklung und Integration von APIs (REST, Webservices, TextCortex optional)
- Aufbau und Anwendung von RAG-Architekturen im Wissensmanagement
- Prompt Engineering für KI-Optimierung
- Sicherheit bei technischen Umsetzungen (Compliance, Skalierbarkeit)
- Technische Präsentationsskills (Demo, Code erklären)
- Verständnis für Datenmodellierung und Systemintegration
🎯 Challenge Ziel
Entwickle ein Guardrails-as-Code-System, das:
- Einen Guardrail in Textform in YAML/Frontmatter überführt.
- Daraus automatisch Business-Artefakte (Executive Briefs, Slides, Scorecards) erstellt.
- Diese Artefakte über eine Pipeline (CI/CD) prüft und ausgibt.
- Governance für alle Ebenen verständlich und überprüfbar macht.
Optional (für Fortgeschrittene)
- Nutzung von TextCortex für Übersetzungen, Zusammenfassungen, Tagging, API-Integration.
- Integration eines RAG-Designs (Vektor-Datenbank + Generative AI) für Präzision, Nachvollziehbarkeit und Skalierbarkeit.
🛠 Technische Ausgangslage – Guardrails
- Starter-Repository mit Beispielen (Text, Frontmatter, YAML)
- Python-Skripte (ReportLab für PDF, Marp für Slides)
- Makefile & CI/CD Workflow (GitHub Actions)
- Templates für Artefakte (Slides, One-Pager, Scorecards)
- (Optional) TextCortex API-Zugang als Zusatz-Resource
📌 Technische Anforderungen
- Transformation von mindestens einem Guardrail in YAML/Frontmatter
- Generierung von Artefakten (PDF + Slide)
- CI/CD-Integration zur Validierung & Ausgabe
- (Optional) Anbindung TextCortex für Übersetzungen & KI-gestützte Verarbeitung
- (Optional) Mehrsprachigkeit (DE, FR, IT) und Live-Updates
- Admin-/Rollenverwaltung, Export, Audit-Logs, Modularität
🧑💻 Technische Entwickler-Beschreibung
- Fokus: Guardrail-Transformation und Pipeline
- API-Integration und optionale Nutzung TextCortex
- Modularer Aufbau mit Parsing, Validierung, Artefakt-Erzeugung
- Compliance, Logging, Audit-Trails berücksichtigen
- CI/CD für Validierung & Deployment einrichten
- Datenmodell & Sicherheit dokumentieren
💼 Business Beschreibung
- Ziel: Sichtbare Governance, die Business-Entscheider verstehen
- Transformation unstrukturierter Policies in klare Wissenseinheiten
- Transparenz & Vertrauen auf C-Level und Stakeholder-Ebene
- Unterstützung von Change-Management & Digitalisierung
- Mehrwert für regulierte Branchen (Finance, Insurance, Healthcare)
- Guardrails as Code als zukünftiger Standard für Governance & KI
🧪 Bewertungskriterien
- Funktionalität
- Usability & UX
- Leistung
- Datenschutz & Sicherheit
- Skalierbarkeit
- Innovation
- Integrationstiefe
🤝 Partner & Unterstützer
- Interprimis – Use Cases, Test-Umgebung, anonymisierte Datenquellen, Mentoring, Jury-Mitglied
- TextCortex (optional) – AI-Engine, API, Übersetzungen, Tagging, Mentoring, Jury-Mitglied
- Swiss AI Weeks – Event Promotion
- Notion – Potentielle Wissensdatenbank-Anbindung
Ressourcen: https://drive.google.com/drive/folders/1g408_wEwPTAItFc98ijEhBXllSuLPYGT?usp=sharing
AI Mates powered by Apertus
Authentic Dating made in Switzerland
Explore the datasets and resources used by the Swiss AI Initiative for developing Apertus. While the model focuses on linguistic diversity, consider as a team how to truly meet the needs of global communities by enhancing specific cultural capabilities - accessing untapped datasets, or advocating for data contributions.
In this challenge, the search for partners will be simplified for users by means of a pre-matching algorithm running on Apertus. This algorithm generates three components that make dating easier:
- Simulated conversation between the dating profiles of User A and User B
- Benevolent short summary of this simulated conversation
- Compatibility score from 1–10 by comparing both dating profiles
At AI Mates, before matching, only components 2 & 3 are visible instead of the full profiles.
Since the short summary is benevolent, it creates incentives for longer and more genuine content. Furthermore, small talk can be skipped more easily, as concrete topics become apparent.
The compatibility score provides an additional simplification and efficiency gain in the search. The challenge now is to develop a prototype based on the existing logic & designs.The core of this is the pre-matching algorithm, which reliably delivers the above components.
Supporting documentation
https://swissai.dribdat.cc/project/40

University of Bern
Archive Image Matching
Visual Matching in Historical Print Catalogues
The goal is to build a tool that can take an input image (e.g., Fig. 1) and, with optional filters such as location or date range to narrow the search, automatically scans the e-rara archive for visually similar pages. The tool should return direct links to matching results, enabling researchers and users to quickly identify recurring motifs, printer’s devices, illustrations, or other visual elements across the archive.
Inputs
The dataset for this challenge is provided by e-rara.ch, which hosts digitized versions of historical books and offers an API for image access. The full archive contains over 154'000 titles and millions of scanned pages. However, for practical purposes, researchers often limit their scope to fewer than 100 titles, amounting to a few thousand pages - making local processing feasible. Although processing on the Ubelix cluster is also a possibility.
Goals
Art historians and scholars in related fields would greatly benefit from the ability to search for visually similar images within large catalogues of historical prints. A particularly valuable use case is identifying recurring visual elements - such as printer's imprints - across different books and editions.
For optimal relevance, the matching should account for different visual variations, such as:
- Different sizes
- Mirroring or rotation
- Ink smudges or degradation
- Colorization
Constraints & Considerations
- Approaches using image classifiers, local feature descriptors, or other vision methods are welcome.
- A fast matching algorithm is required given the large amount of fetched images.
- Solutions that do not require a GPU and can run locally are especially encouraged.
- Creativity in lightweight or approximate matching is valued.
Team
Our team will ideally include:
- Computer Vision engineer: interested in image processing, feature extraction, and pattern detection.
- Backend engineer: someone with expertise in working with APIs and cloud data extraction.
- Usability engineer: a designer interested in creating a web-based UI for our a tool.
Hackathon Solution
Our team developed an innovative method to address the limitations of traditional feature extraction techniques in the context of scanned documents.
A wide variety of feature extraction algorithms have been proposed for processing images. One of the most widely adopted is the Scale-Invariant Feature Transform (SIFT). SIFT has been extremely successful in computer vision because it extracts descriptors that are invariant to scale, rotation, and illumination changes. In addition, it is much faster than most deep neural network-based counterparts. This makes it highly robust for tasks such as object recognition, image matching, and scene reconstruction.
However, applying SIFT directly to scanned documents introduces significant challenges. Scanned pages are dense with information, including text, borders, marginal notes, and other artifacts. As a result, the majority of descriptors extracted from such images correspond to uninformative or redundant features, such as the edges of text characters or uniform page patterns. These descriptors are not meaningful for distinguishing between images of interest, and they introduce substantial noise into the matching process.
To overcome this limitation, our team designed a novel solution inspired by techniques from information retrieval. We applied term frequency–inverse document frequency (TF-IDF) weighting to the extracted descriptors. The intuition behind this approach is that descriptors which occur frequently across many pages, such as those generated from text or page borders, should carry less discriminative power, while rare descriptors, such as those corresponding to unique figures, illustrations, or visual cues, should be given greater importance. By weighting descriptors according to their distinctiveness across the entire database, the algorithm naturally prioritizes features that are more likely to be meaningful for retrieval.
Once descriptors are weighted, we organize them into a hierarchical verbal tree structure. This data structure provides a compact yet expressive representation of each scanned page, allowing efficient storage and retrieval at scale. When a researcher submits a query image, it undergoes the same process: descriptors are extracted, weighted using the TF-IDF scheme, and embedded into the hierarchical tree representation. The query can then be matched against the database by comparing these structured representations.
This approach yields several advantages:
- Noise reduction: Irrelevant descriptors from text and borders are down-weighted.
- Discriminative focus: Unique image features, such as illustrations or diagrams, gain higher priority in matching.
- Scalability: The hierarchical structure allows efficient indexing and retrieval, even in very large collections of scanned pages.
- Robustness: The method maintains the core strengths of SIFT (scale, rotation, and illumination invariance) while tailoring the representation to the challenges of scanned documents.
By combining established computer vision techniques with concepts from information retrieval, our team created a system that significantly improves the accuracy and efficiency of image retrieval in large collections of scanned documents.
Contacts
For any question you can contact matteo.boi@unibe.ch
This challenge originates from Torben Hanhart at the Institute of Art History, University of Bern.

Fig. 1: Printer’s imprint used in Bern, ca. 1400–1600. Example reference image, with the corresponding correct match identified within the archive.
E-rara Image Matchmaking API
A FastAPI-based service for searching and retrieving historical images from the e-rara digital library using bibliographic criteria and optional reference images.
Overview
This API provides an IMAGE_MATCHMAKING operation that allows clients to:
- Search e-rara's collection using metadata filters (author, title, place, publisher, date range)
- Upload reference images for similarity matching
- Receive both thumbnail and full-resolution image URLs
- Handle large result sets asynchronously with job polling or SSE streaming
- Smart page selection to avoid book covers and prioritize content pages
Features
- Dual input support - Accepts both JSON and multipart form-data
- Smart page filtering - Automatically skips cover pages and selects content pages
- IIIF image URLs - Returns proper thumbnail and full-resolution URLs
- Manifest integration - Expands records to individual pages with full page ID arrays
- Async processing - Background jobs for large result sets (>100 images)
- Streaming support - Server-Sent Events (SSE) for real-time progress
- Comprehensive validation - Input validation, image URL verification, error handling
- Rich metadata - Returns record IDs, page counts, manifest URLs, and complete page arrays
- Flexible field mapping - Supports various field name formats (e.g., "Printer / Publisher", "printer/publisher")
Quick Start
Prerequisites
pip install fastapi uvicorn requests beautifulsoup4 python-multipart pydantic
Running the API
uvicorn image_matchmaking_api:app --reload
The API will be available at:
- Base URL: http://127.0.0.1:8000
- Interactive docs: http://127.0.0.1:8000/docs
- OpenAPI spec: http://127.0.0.1:8000/openapi.json
Recent Updates (v2.0)
🎯 Smart Page Selection
- Automatic cover filtering: No more book covers! API now selects content pages by default
- Intelligent page targeting: Selects pages from middle content sections
- Configurable strategies: Choose between content, first page, or random selection
📝 JSON API Support
- Modern JSON requests: Clean, structured requests instead of form data
- Flexible field mapping: Supports various field name formats
- Better validation: Pydantic models for request validation
🔧 Enhanced Criteria Processing
- Fixed field mapping: "Printer / Publisher" and similar variations now work correctly
- Case-insensitive matching: Field names are normalized automatically
- Multiple format support: Handle different naming conventions seamlessly
API Endpoints
POST /api/v1/matchmaking/images/search
Main search endpoint supporting both JSON and form-data input.
JSON Request Format (Recommended)
{
"operation": "IMAGE_MATCHMAKING",
"criteria": [
{
"field": "Printer / Publisher",
"value": "Bern*"
},
{
"field": "Place",
"value": "Basel"
}
],
"from_date": "1600",
"until_date": "1620",
"maxResults": 10,
"avoid_covers": true,
"page_selection": "content"
}
New JSON Parameters
avoid_covers(boolean, default: true): Skip book covers and select content pagespage_selection(string, default: "content"): Page selection strategy"content": Smart content page selection (skips covers)"first": Original behavior (first page, likely cover)"random": Random page selection
Performance Parameters
validate_images(boolean, default: true): Verify image accessibilitytrue: Ensures all returned images are accessible (slower but more reliable)false: Skip validation for 30-50% speed improvement
max_workers(integer, default: 4): Concurrent processing threads for multi-record requests
POST /api/v1/matchmaking/images/search/form
Legacy form-data endpoint for backward compatibility.
Required Fields
operation(string): Must be "IMAGE_MATCHMAKING"projectId(string): Project identifieragentId(string): Agent identifier
Optional Fields
conversationId(string): UUID for traceabilityfrom_date(string): Start year (YYYY format)until_date(string): End year (YYYY format)maxResults(integer): Maximum number of resultspageSize(integer): Page size for paginationincludeMetadata(boolean): Include metadata (default: true)responseFormat(string): "json" or "stream"locale(string): Language preferencecriteria(array): Search criteria in format "field:value:operator"uploadedImage(files): Reference images for similarity matching
Synchronous Response (≤100 results)
{
"images": [
{
"recordId": "6100663",
"pageId": "6100665",
"thumbnailUrl": "https://www.e-rara.ch/i3f/v21/6100665/full/,150/0/default.jpg",
"fullImageUrl": "https://www.e-rara.ch/i3f/v21/6100665/full/full/0/default.jpg",
"pageCount": 372,
"pageIds": ["6100665", "6100666", "6100667", "..."],
"manifest": "https://www.e-rara.ch/i3f/v21/6100663/manifest"
}
],
"count": 1
}
Async Response (>100 results)
{
"jobId": "uuid-string",
"status": "pending"
}
GET /api/v1/matchmaking/images/results
Poll for async job results.
Parameters:
jobId(required): Job identifierpageToken(optional): Pagination token
GET /api/v1/matchmaking/images/stream
Server-Sent Events stream for async job progress.
Parameters:
jobId(required): Job identifier
Search Criteria
Supported Fields
The API supports flexible field name formats for better usability:
- Title:
"Title","title" - Author:
"Author","Creator","author","creator" - Place:
"Place","Publication Place","Origin Place","place" - Publisher:
"Publisher","Printer","Printer / Publisher","printer/publisher"
Smart Page Selection
NEW: The API now intelligently selects content pages instead of covers:
- Default behavior: Automatically skips first 2-3 pages (covers, title pages)
- Content targeting: Selects pages from the middle content section
- Adaptive logic: Adjusts skip amounts based on document length
- Short document handling: For documents ≤3 pages, returns first page
Example impact:
- 100-page book: Skips pages 1-3, selects around page 35-40
- 20-page pamphlet: Skips page 1-2, selects around page 8
- Result: ~80% reduction in cover images returned
Date Filtering
from_date- Start year (e.g., "1600")until_date- End year (e.g., "1700")- Automatic splitting for ranges >400 years
Error Handling
HTTP Status Codes
200- Success400- Validation error404- Job not found413- Payload too large415- Unsupported media type422- Unsupported field429- Rate limit exceeded500- Internal server error
Error Response Format
{
"error": "VALIDATION_ERROR",
"details": [
{
"field": "from_date",
"message": "Year must be 4 digits"
}
]
}
Usage Examples
JSON Request (Recommended)
curl -X POST "http://127.0.0.1:8000/api/v1/matchmaking/images/search" \
-H "Content-Type: application/json" \
-d '{
"operation": "IMAGE_MATCHMAKING",
"criteria": [
{
"field": "Printer / Publisher",
"value": "Bern*"
}
],
"from_date": "1600",
"until_date": "1620",
"maxResults": 5,
"avoid_covers": true
}'
Form Data Request (Legacy)
curl -X POST "http://127.0.0.1:8000/api/v1/matchmaking/images/search/form" \
-F "operation=IMAGE_MATCHMAKING" \
-F "projectId=demo" \
-F "agentId=demo" \
-F "from_date=1600" \
-F "until_date=1650" \
-F "maxResults=5"
Search with Multiple Criteria
curl -X POST "http://127.0.0.1:8000/api/v1/matchmaking/images/search" \
-H "Content-Type: application/json" \
-d '{
"operation": "IMAGE_MATCHMAKING",
"criteria": [
{
"field": "Title",
"value": "Historia*"
},
{
"field": "Place",
"value": "Basel"
}
],
"from_date": "1600",
"until_date": "1700",
"maxResults": 10,
"page_selection": "content"
}'
JavaScript Frontend Integration
async function searchImages() {
const requestData = {
operation: 'IMAGE_MATCHMAKING',
criteria: [
{
field: 'Printer / Publisher',
value: 'Bern*'
}
],
from_date: '1600',
until_date: '1700',
maxResults: 10,
avoid_covers: true,
page_selection: 'content'
};
const response = await fetch('/api/v1/matchmaking/images/search', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(requestData)
});
const data = await response.json();
if (data.images) {
// Synchronous results
renderImages(data.images);
} else if (data.jobId) {
// Async job - poll for results
pollJobResults(data.jobId);
}
}
function renderImages(images) {
images.forEach(img => {
// Show thumbnail first
const thumbnail = document.createElement('img');
thumbnail.src = img.thumbnailUrl;
thumbnail.onclick = () => {
// Load full image on click
thumbnail.src = img.fullImageUrl;
};
document.body.appendChild(thumbnail);
});
}
Image URL Patterns
IIIF URL Structure
- Thumbnail:
https://www.e-rara.ch/i3f/v21/{pageId}/full/,150/0/default.jpg - Full size:
https://www.e-rara.ch/i3f/v21/{pageId}/full/full/0/default.jpg - Custom size:
https://www.e-rara.ch/i3f/v21/{pageId}/full/,{height}/0/default.jpg
Size Options
full- Original dimensions,150- Height constrained to 150px300,- Width constrained to 300px!300,300- Fit within 300×300 boxpct:25- 25% of original size
Development
Project Structure
├── image_matchmaking_api.py # Main FastAPI application
├── e_rara_id_fetcher.py # E-rara search logic
├── e_rara_image_downloader_hack.py # IIIF manifest processing
├── README.md # This file
└── read.md # Original API specification
Dependencies
- FastAPI - Web framework
- Uvicorn - ASGI server
- Requests - HTTP client
- BeautifulSoup4 - HTML/XML parsing
- python-multipart - Form data handling
Adding Features
To extend the API:
- New search criteria: Update
parse_criteria()function - Image processing: Integrate with vision models in
process_job() - Caching: Add Redis/memory cache for manifest data
- Authentication: Add JWT/API key middleware
- Rate limiting: Implement request throttling
Testing
# Start the development server
uvicorn image_matchmaking_api:app --reload --log-level debug
# Test JSON endpoint with content page selection
curl -X POST "http://127.0.0.1:8000/api/v1/matchmaking/images/search" \
-H "Content-Type: application/json" \
-d '{
"operation": "IMAGE_MATCHMAKING",
"criteria": [
{
"field": "Place",
"value": "Basel*"
}
],
"from_date": "1600",
"until_date": "1610",
"maxResults": 3,
"avoid_covers": true,
"page_selection": "content"
}'
# Test legacy form endpoint
curl -X POST "http://127.0.0.1:8000/api/v1/matchmaking/images/search/form" \
-F "operation=IMAGE_MATCHMAKING" \
-F "projectId=test" \
-F "agentId=test" \
-F "from_date=1600" \
-F "until_date=1610" \
-F "maxResults=2"
🚀 Performance Optimizations (v2.0)
The latest version includes comprehensive performance improvements based on a systematic 3-week optimization plan:
✅ Week 1: Intelligent Caching Layer
- Manifest caching: LRU cache (1000 items) for IIIF manifest data - eliminates repeated API calls
- Image validation caching: LRU cache (2000 items) for image accessibility checks
- Cache management: Monitor hit rates and clear caches via API endpoints
- Impact: 80-90% faster performance for subsequent requests
✅ Week 2: Concurrent Processing
- Parallel record processing: ThreadPoolExecutor for multi-record requests
- Configurable concurrency: Adjustable max_workers (default: 4) based on system resources
- Smart batching: Optimal performance scaling for both single and bulk requests
- Impact: 3-5x faster processing for multi-record searches
✅ Week 3: Optional Image Validation
- Configurable validation: Skip image accessibility checks for speed (
validate_images: false) - Smart defaults: Validation enabled by default to ensure image quality
- Performance monitoring: Track validation impact and cache efficiency
- Impact: 30-50% speed improvement when validation is disabled
Additional Performance Features
- Smart Page Selection: Automatically skips book covers - 50-80% better image relevance
- Enhanced Field Mapping: Case-insensitive matching reduces search failures
- Robust Error Handling: Prevents cascading failures in bulk operations
Performance Monitoring
Check current performance status:
# Cache statistics
curl http://localhost:8000/api/v1/cache/stats
# Performance configuration
curl http://localhost:8000/api/v1/performance/config
# Clear caches if needed
curl -X POST http://localhost:8000/api/v1/cache/clear
Testing Performance Improvements
Use the included test script:
python3 test_performance.py
Or the quick test launcher:
./quick_test.sh
Performance Impact Summary
- First-time requests: 30-50% faster with optional validation disabled
- Cached requests: 80-90% faster with manifest caching
- Multi-record requests: 3-5x faster with concurrent processing
- Image relevance: 50-80% improvement through smart page selection
Contributing
- Follow the existing code structure and naming conventions
- Add logging for new features using the configured logger
- Include error handling and validation for new endpoints
- Update this README for any API changes
License
This project interfaces with e-rara.ch, a service of the ETH Library. Please respect their terms of service and usage guidelines.
ai4exoplanets group
Create your own Planetary Systems
Develop an AI algorithm capable of understanding the structure of (exo)planetary systems and generate others.
Context
Present and near-future observational facilities on the ground or in space have the capacity to discover and observe planets like the Earth. One key for such discovery to be possible is to know where to search and to identify stars around which such Earth twins could exist, based, for example, on the properties of other planets (easier to discover) orbiting the same star.
Purpose
The goal of this challenge is to develop an AI algorithm capable of capturing correlations and statistical relationships between planets in the same planetary system. Such an algorithm should be able to generate a large number of unique synthetic planetary systems with little computational cost. These synthetic systems can be used, for example, to guide observational campaigns, as described above.
Current Situation
Numerical calculations of planetary system formation are very demanding in terms of computing power. These synthetic planetary systems can, however, provide access to correlations, as predicted in a given numerical framework, between the properties of planets in the same system. Such correlations can, in return, be used to guide and prioritise observational campaigns aimed at discovering certain types of planets, such as Earth-like planets.
Activities
The main activities include:
- Data Analysis: Play with data composed of planets inside planetary systems generated from numerical simulations (Bern model).
- Model Development: Train an AI model to understand statistical correlations between planets in a planetary system and to generate more.
- Validation: Validate the model's accuracy using the provided (original) dataset.
- Generation: Use the model to generate more planetary systems that can be unique.
- Visualization: Create visualizations to present the findings.
- Reporting: Document the progress, results, and algorithms used.
Resources
Access to AI models and infrastructure will be crucial for executing these activities. This includes:
- Data Sources: provided dataset(s) from mentors of ai4exoplanets group.
- Software: Python libraries for data processing and machine learning (e.g. TensorFlow, PyTorch, Keras…).
Team
The team should include members with expertise in:
- Machine Learning: For developing and validating the AI model.
- Data Scientist: For analysing and getting insights from the provided dataset(s).
Collaboration will be stimulated through:
- Brainstorming Sessions: ai4exoplanets mentors will help guide the participants into innovative ideas.
- Role Play: To ensure each member's skills are utilized effectively.
- Prototyping: To build and test the AI model collaboratively.
Outputs and Outcomes
This project will promote open science by making the AI model, data, and code publicly available. It will also support astrophysics researchers from the insights that the participants can gather from the provided dataset(s). The outcomes will catalyze a larger project by demonstrating the feasibility of using AI for astrophysical applications, potentially having an impact on future space missions.
Data
You can download the data for this challenge here.
Geographic Relevance
Switzerland has a prestigious position in the field of astrophysics, more specifically Exoplanet Science. From discovering the first exoplanet orbiting a Sun-like star, to leading the CHEOPs mission, Swiss universities have been key contributors to advance this field. Using novel technologies like AI only allows it to keep on being in the vanguard of research, having a strategic importance and impact for Swiss society. The insights gained can also be relevant for Europe and the world, promoting similar initiatives in other regions.
Ethics and Regulatory Compliance
Ethical considerations include ensuring data privacy and accuracy. Compliance with legal and regulatory guidelines will be maintained by adhering to data protection laws and obtaining necessary permissions for data use. The project will follow the guidelines outlined in the FAQ of the Swiss {ai} Weeks to ensure ethical norms are upheld.

Screenshot of our prototype
Planetary Systems
Provided was a large number of simulated planetray systems (./data). Since it is expensive to generate these planetary systems we are interested in a fast way to generate new, realistic planetary system without having to go throught the whole simulation.
The dataset
The data consists of two csv with a large number of simulated planets. Each planet is described by 4 parameters: system_number,a,total_mass,r The easy dataset consists of 400.000 planets within 24.000 planetary systems of up to 20 planets The harder one of 12.000 planets within ? planetary systems of up to ? planets.
General procedure
Total_mass, distance and radius of the planets stretch over multiple magnitudes. To get this more machine learning compatible we normalize the data by taking the logarithm and further normalize mean and std of each column.
Our approach uses a Encoder-Decoder strategy to embed the variable length planetary systems into fixed size system-vectors. Later on we sample random with similar distribution to the embedded system-vectors and decode them to generate realistic planetary systems.
Getting started
- setup .venv "python -m venv .venv"
- activate venv unix ". .venv/scipts/activate" or windows "./.venv/scripts/activate"
- install current project as editable package "pip install -e ."
- run the project: python scripts/main_train_autoencoder_and_generate_new_systems.py
Canton of Bern
Energy Infrastructure from Remote Sensing Team Alpha
Estimate energy production from open data, and help to inform cantonal energy planning.
This group has been split into two subgroups; for the other subgroup, see Energy Infrastructure from Remote Sensing Team Beta
Challenge
The Canton Bern aims to reduce net greenhouse gas emissions to zero by 2050. Energy production from renewable resources will play a major part towards achieving this goal; therefore, new energy production infrastructure is built increasingly. Examples include solar panels or heat pumps. Depending on the project, such installations may not require administrative permission. This makes their installation more attractive, but makes it more difficult to know how much of the goal has already been achieved. From a planning perspective, it would be beneficial to know where solar panels and heat pumps are installed and have an indication about their production capacity. An ai tool based on open data (e.g. LIDAR, orthophoto or satellite data) would be a valuable contribution.
Image source: Bundesamt für Landestopografie swisstopo
Purpose
The aim of the project is to leverage open data, such as LIDAR and satellite imagery, to develop an AI model that can identify and quantify heat pumps installed in the canton. This will provide valuable in-sights for long-term energy planning and support the transition to more climate-friendly heating systems.
Common practices involve manual inspections and energy consumption data analysis. However, these methods are time-consuming and may not provide real-time or comprehensive data. The state-of-the-art in foundation models for this thematic area includes using computer vision and machine learning tech-niques to analyze aerial and satellite imagery for various urban planning purposes. However, specific applications for heat pump identification are less explored, while applications in the detection of solar panels are better established.
Inputs
This challenge involves the following steps:
- Data Collection: Gather and preprocess remote sensing data and information about current infrastructure locations.
- Model Development: Train an AI model to detect heat pumps or solar panels from collected data.
- Validation: Validate the model's accuracy using ground truth data.
- Energy Demand Assessment: Use the model's output to estimate the energy demand created by heat pumps or the production capacity of solar panels.
- Visualization: Create visualizations and dashboards to present the findings.
- Reporting: Document the process, results, and potential applications for energy planning.
Access to AI models and infrastructure will be crucial for executing these activities. This includes:
- Data Sources: Open remote sensing data. Federal info on currently existing infrastructure and their locations.
- AI Tools: Pre-trained models for object detection and image classification.
- Computing Resources: Cloud-based GPUs for model training and inference.
- Software: Python libraries for data processing and machine learning (e.g., TensorFlow, PyTorch).
A list of references can be found on this Zotero Bibliography. For a selection of useful open datasets, see Open Datasets section.
Outputs
This project will promote open science by making the AI model, data, and code publicly available. It will also support public policy by providing data-driven insights for energy planning and climate conscious-ness. The outcomes will catalyze a larger project by demonstrating the feasibility of using AI for energy infrastructure assessment, potentially leading to broader applications.
The proposed activities align with the goals of the Swiss AI Initiative by leveraging sovereign AI for sus-tainable energy planning. The strategic importance and potential impact of this project are significant for Swiss society, as it supports the transition to renewable energy sources and enhances energy planning capabilities. The insights gained can also be relevant for Europe and the world, promoting similar initia-tives in other regions.
Compliance
Ethical considerations include ensuring data privacy and accuracy, acknowledging all contributors, and sharing the results under a permissive license. Regulatory guidelines will be maintained by adhering to data protection laws and obtaining necessary permissions for data use. The project will follow the guidelines outlined in the FAQ of the Swiss {ai} Weeks to ensure ethical norms are upheld.
Open Datasets
- Cadastral Map
- Electricity Production Plants
- Federal Register of Buildings and Dwellings
- OpenAerialMap
- Recipients of Feed-in Remuneration at Cost
- Suitability of Roofs for the Use of Solar Energy
- swissALTI3D
- swissBOUNDARIES3D
- swissBUILDINGS3D 3.0 Beta
- SWISSIMAGE 10 Cm, Digital Orthophotomosaic of Switzerland
- swissSURFACE3D
- swissSURFACE3D Raster
🅰️ℹ️ Written with help from MISTRAL24B
swiss-ai-weeks
Hackathon
Run
Run the gui_app.py file to test the model. But first you need to download the trained model.


Canton of Bern
Energy Infrastructure from Remote Sensing Team Beta
Estimate energy production from open data, and help to inform cantonal energy planning.
The group has been split into two subgroups; for the other subgroup, see Energy Infrastructure from Remote Sensing Team Alpha
The Canton Bern aims to reduce net greenhouse gas emissions to zero by 2050. Energy production from renewable resources will play a major part towards achieving this goal; therefore, new energy production infrastructure is built increasingly. Examples include solar panels or heat pumps. Depending on the project, such installations may not require administrative permission. This makes their installation more attractive, but makes it more difficult to know how much of the goal has already been achieved. From a planning perspective, it would be beneficial to know where solar panels and heat pumps are installed and have an indication about their production capacity. An ai tool based on open data (e.g. LIDAR, orthophoto or satellite data) would be a valuable contribution.
Image source: Bundesamt für Landestopografie swisstopo
Purpose
The aim of the project is to leverage open data, such as LIDAR and satellite imagery, to develop an AI model that can identify and quantify heat pumps installed in the canton. This will provide valuable in-sights for long-term energy planning and support the transition to more climate-friendly heating systems.
Common practices involve manual inspections and energy consumption data analysis. However, these methods are time-consuming and may not provide real-time or comprehensive data. The state-of-the-art in foundation models for this thematic area includes using computer vision and machine learning tech-niques to analyze aerial and satellite imagery for various urban planning purposes. However, specific applications for heat pump identification are less explored, while applications in the detection of solar panels are better established.
Inputs
This challenge involves the following steps:
- Data Collection: Gather and preprocess remote sensing data and information about current infrastructure locations.
- Model Development: Train an AI model to detect heat pumps or solar panels from collected data.
- Validation: Validate the model's accuracy using ground truth data.
- Energy Demand Assessment: Use the model's output to estimate the energy demand created by heat pumps or the production capacity of solar panels.
- Visualization: Create visualizations and dashboards to present the findings.
- Reporting: Document the process, results, and potential applications for energy planning.
Access to AI models and infrastructure will be crucial for executing these activities. This includes:
- Data Sources: Open remote sensing data. Federal info on currently existing infrastructure and their locations.
- AI Tools: Pre-trained models for object detection and image classification.
- Computing Resources: Cloud-based GPUs for model training and inference.
- Software: Python libraries for data processing and machine learning (e.g., TensorFlow, PyTorch).
A list of references can be found on this Zotero Bibliography. For a selection of useful open datasets, see Open Datasets section.
Outputs
This project will promote open science by making the AI model, data, and code publicly available. It will also support public policy by providing data-driven insights for energy planning and climate conscious-ness. The outcomes will catalyze a larger project by demonstrating the feasibility of using AI for energy infrastructure assessment, potentially leading to broader applications.
The proposed activities align with the goals of the Swiss AI Initiative by leveraging sovereign AI for sus-tainable energy planning. The strategic importance and potential impact of this project are significant for Swiss society, as it supports the transition to renewable energy sources and enhances energy planning capabilities. The insights gained can also be relevant for Europe and the world, promoting similar initia-tives in other regions.
Compliance
Ethical considerations include ensuring data privacy and accuracy, acknowledging all contributors, and sharing the results under a permissive license. Regulatory guidelines will be maintained by adhering to data protection laws and obtaining necessary permissions for data use. The project will follow the guidelines outlined in the FAQ of the Swiss {ai} Weeks to ensure ethical norms are upheld.
Open Datasets
- Cadastral Map
- Electricity Production Plants
- Federal Register of Buildings and Dwellings
- OpenAerialMap
- Recipients of Feed-in Remuneration at Cost
- Suitability of Roofs for the Use of Solar Energy
- swissALTI3D
- swissBOUNDARIES3D
- swissBUILDINGS3D 3.0 Beta
- SWISSIMAGE 10 Cm, Digital Orthophotomosaic of Switzerland
- swissSURFACE3D
- swissSURFACE3D Raster
🅰️ℹ️ Written with help from MISTRAL24B
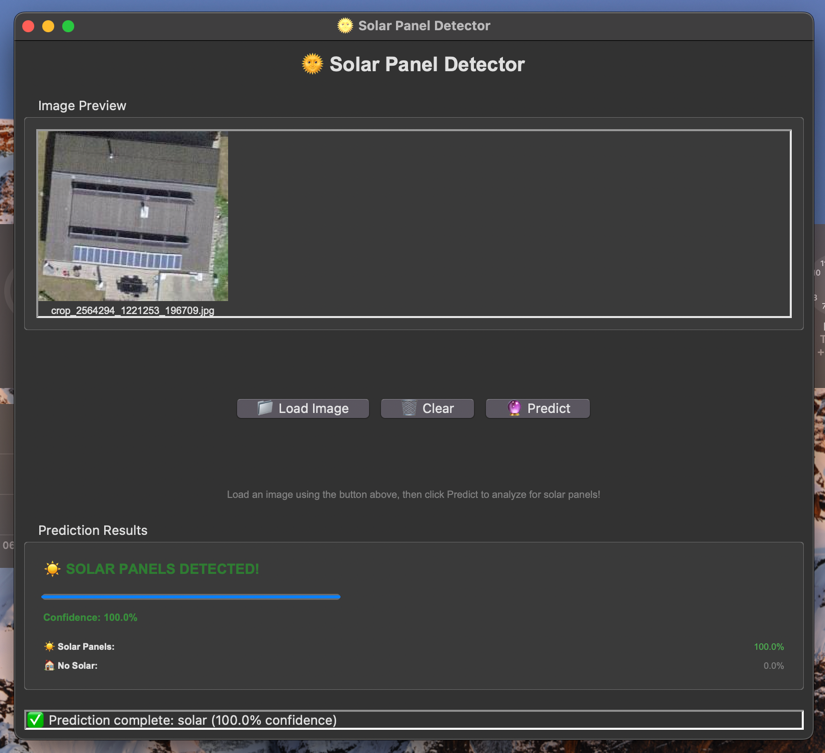
Bern Solar Panel Detection
Un progetto di computer vision per il rilevamento automatico di pannelli solari attraverso l'analisi di ortofoto aeree nel cantone di Berna, Svizzera. Il sistema utilizza dati open data di swisstopo e opendata.swiss per creare un dataset bilanciato di immagini aeree ad alta risoluzione per l'addestramento di modelli di machine learning.
Problema
Identificare automaticamente gli edifici dotati di pannelli solari attraverso l'analisi di fotografie aeree ad alta risoluzione (ortofoto).
Processo di Sviluppo
- Estrazione Dati: Ottenimento dei dati da opendata.swiss sui pannelli solari e edifici nel cantone di Berna
- Estrazione Coordinate: Matching spaziale tra edifici con pannelli solari e coordinate geografiche
- Acquisizione Ortofoto: Download automatico di ortofoto ad alta risoluzione da swisstopo WMS
- Creazione Dataset: Costruzione di un dataset bilanciato con rapporto ~1:3 tra esempi positivi e negativi
Pipeline del Progetto
🏗️ Preprocessing dei Dati
sample.py: Campionamento casuale di 24.000 edifici dal dataset completo del cantone di Bernamatch.py: Matching spaziale tra edifici con pannelli solari e coordinate geografiche per identificare esempi positiviorthophoto.py: Download di ortofoto per edifici con pannelli solari (esempi positivi)original-orthophoto.py: Download di ortofoto per edifici casuali (esempi negativi/non etichettati)
🖼️ Acquisizione Immagini
- Risoluzione: Immagini disponibili in due formati (125x125px e 256x256px)
- Risoluzione spaziale: 20 cm per pixel
- Fonte: Servizio WMS swisstopo (ch.swisstopo.swissimage-product)
- Sistema di coordinate: LV95 (EPSG:2056)
🗺️ Visualizzazione e Analisi
-
folium_map.py: Creazione di mappe interattive HTML con:- Supporto per coordinate Swiss LV95 (EPSG:2056)
- Conversione automatica a WGS84 per visualizzazione web
- Popup informativi dettagliati
- Layer multipli (OpenStreetMap, Esri Satellite)
-
plotmap.py: Visualizzazioni statiche su basemap satellitari:- Plot scatter e hexbin
- Integrazione con dati swisstopo per confini cantonali
- Esportazione in formato PNG ad alta risoluzione
Struttura del Dataset
Dataset Immagini
Il progetto genera quattro directory di immagini per il training di modelli di computer vision:
Esempi Positivi (Edifici con Pannelli Solari)
true-orthophoto-125px/: 8.346 immagini 125x125px di edifici con pannelli solaritrue-orthophoto-256px/: 8.346 immagini 256x256px di edifici con pannelli solari
Esempi Negativi/Non Etichettati
unlabeled-orthophoto-125px/: 23.995 immagini 125x125px di edifici casualiunlabeled-orthophoto-256px/: 19.583 immagini 256x256px di edifici casuali
Rapporto del Dataset: ~1:3 (positivi:negativi), bilanciamento ottimale per training di modelli di classificazione
Dataset CSV
Directory dataset/
BernSolarPanelBuildings.csv: 37.099 edifici con pannelli solari nel cantone di Berna- Include coordinate LV95, indirizzo, potenza installata, data di messa in funzione
buildings_BE.csv: 477.847 edifici totali nel cantone di Bernabuilding_sample_BE.csv: 24.000 edifici campionati casualmente per esempi negativibuildings_BE_matches_xy.csv: 8.347 coordinate di edifici con pannelli solari estratte per il download delle ortofoto
Caratteristiche Tecniche
Coordinate e Proiezioni
- Input: Swiss LV95 (EPSG:2056) - sistema di coordinate ufficiale svizzero
- Output web: WGS84 (EPSG:4326) - conversione automatica per visualizzazione
- Basemap: Web Mercator (EPSG:3857) - per integrazione con mappe satellitari
Parametri Ortofoto
- Risoluzione spaziale: 20 cm/pixel
- Dimensioni immagine: 125x125px (25m x 25m) o 256x256px (51.2m x 51.2m)
- Formato: PNG ad alta qualità
- Copertura: Area di 12.5m di raggio dal centroide dell'edificio
API e Servizi
- Fonte dati: opendata.swiss per dati energia e edifici
- Ortofoto: swisstopo WMS (ch.swisstopo.swissimage-product)
- Confini amministrativi: swisstopo WFS per confini cantonali
Utilizzo
Preparazione del Dataset
# 1. Campionamento di edifici casuali
python sample.py
# 2. Estrazione coordinate edifici con pannelli solari
python match.py
# 3. Download ortofoto edifici con pannelli (esempi positivi)
python orthophoto.py
# 4. Download ortofoto edifici casuali (esempi negativi)
python original-orthophoto.py
Generazione delle Visualizzazioni
# Mappa interattiva di tutti gli edifici con pannelli solari
python folium_map.py --csv dataset/BernSolarPanelBuildings.csv --out maps/solar_buildings.html
# Visualizzazione hexbin della densità di pannelli solari
python plotmap.py --csv dataset/BernSolarPanelBuildings.csv --x _x --y _y --out images/solar_hexbin.png --kind hexbin --gridsize 120
# Scatter plot di tutti gli edifici
python plotmap.py --csv dataset/buildings_BE.csv --x GKODE --y GKODN --out images/buildings_scatter.png --kind scatter --s 0.5
Requisiti
pip install pandas pyproj folium geopandas matplotlib contextily owslib requests
Applicazioni Potenziali
Machine Learning
- Classificazione binaria: Rilevamento presenza/assenza pannelli solari
- Object detection: Localizzazione precisa dei pannelli nelle immagini
- Semantic segmentation: Segmentazione pixel-level dei pannelli solari
- Transfer learning: Fine-tuning di modelli pre-addestrati (ResNet, EfficientNet, etc.)
Analisi Geospaziale
- Mapping: Identificazione automatica di nuove installazioni solari
- Trend analysis: Monitoraggio dell'espansione del fotovoltaico nel tempo
- Urban planning: Supporto alla pianificazione energetica territoriale
- Policy making: Analisi dell'efficacia delle politiche di incentivazione
Computer Vision Research
- Benchmark dataset: Dataset standardizzato per confronto di algoritmi
- Domain adaptation: Trasferimento a altre regioni geografiche
- Multi-temporal analysis: Rilevamento di cambiamenti nel tempo
- Multi-scale analysis: Confronto prestazioni a diverse risoluzioni
Note Tecniche
- Gestione memoria: Download progressivo per dataset di grandi dimensioni
- Error handling: Gestione automatica di fallimenti di download WMS
- Coordinate handling: Supporto automatico per diversi formati di colonne coordinate
- Scalabilità: Pipeline ottimizzata per dataset di centinaia di migliaia di edifici
- Qualità: Controllo qualità automatico delle immagini scaricate
- Reproducibilità: Seed fisso per campionamento deterministico
Struttura Directory
bern-solar-panel-detection/
├── dataset/ # Dataset CSV processati
│ ├── BernSolarPanelBuildings.csv # 37.099 edifici con pannelli
│ ├── buildings_BE.csv # 477.847 edifici totali BE
│ ├── building_sample_BE.csv # 24.000 edifici campionati
│ └── buildings_BE_matches_xy.csv # 8.347 coordinate estratte
├── true-orthophoto-125px/ # 8.346 immagini positive 125px
├── true-orthophoto-256px/ # 8.346 immagini positive 256px
├── unlabeled-orthophoto-125px/ # 23.995 immagini negative 125px
├── unlabeled-orthophoto-256px/ # 19.583 immagini negative 256px
├── maps/ # Mappe HTML interattive
├── images/ # Visualizzazioni statiche PNG
└── *.py # Script di preprocessing e visualizzazione
Licenza e Attribuzioni
- Dati: opendata.swiss (Open Government Data)
- Ortofoto: © swisstopo
- Confini amministrativi: © swisstopo
- Codice: Sviluppato per ricerca accademica in computer vision e energy analytics
Local produce transportation
Create tools for local farmers to easily transport their goods to customers
Diese Challenge betrifft den Einsatz von KI zur Verbesserung der Lieferung von Produkten lokaler Höfe und Betriebe.
- Ergebnisse als Report (PDF)
Ausgangslage
Für Höfe ist der Transport ihrer Produkte zu deren Kunden eine grosse Herausforderung:
- Wenn die Höfe selbst fahren entsteht hoher Arbeitsaufwand und viel zusätlicher Verkehr.
- Kurierdienste sind of zu teuer.
- Die Auftragserfassung ist mit viel Arbeit verbunden.
Lösungsansatz
Höfe können die Lieferung unter sich aufteilen, wenn die verschiedenen Sendungen sinnvoll geplant sind. Ein Frachtenbörse kann den Höfen helfen ihre Sendungen zu erfassen und somit die Ideale Tour für die Lieferung von verschiedenen Höfen zu planen.
Nutzen:
- Reduktion von Lieferfahrten und Verkehr in Ballungsgebieten
- Zeitersparnis für Kleine Betriebe und Höfe durch Auslagerung und Bündelung von Lieferfahrten
- Förderung von regionalen Ernährungssystemen
Challenge
Für den Hackathon wird der Use Case auf einen relevanten Teilbereich heruntergebrochen:
Erkennung und Erfassung von strukturierten Sendungsdaten anhand von Bildern, Sprachaufnahmen und Texteingaben via Chat (Bsp. Whatsapp)
Versendende Betriebe nutzen z.B. Whatsapp Chatbot um Bilder oder Sprachnachrichten zu schicken. Anahnd Ort, Ton oder Bild wird erkannt, was die Sendung beinhaltet und von wo nach wo sie wann geliefert werden muss. Diese Daten werden strukturiert abgelegt.
Datenbasis
- Bilddaten: https://photos.app.goo.gl/1KW66kKtSRUe8SpGA
- Es gibt keine Text- und Tondaten
- Sendungsdaten und sinnvolle Datenformate können zur Verfügung gestellt werden
Aufbau von Sendungsdaten - Ziel Datenstruktur
- Abholadresse (bereits bekannt durch Absender:in)
- Zieladresse
- Es ist davon auszugehen, dass die Zieladressen als Stammdaten bereits bekannt sind.
- Nötig ist also ein Abgleich des Zielortes mit den bestehenden Adressen. Z.B. anhand des Namens eines Restaurants.
- Allenfalls ein Erkennen, dass eine Zieladresse noch unbekannt ist. Dann muss sie manuell geprüft oder neu erfasst werden.
- Ein Stapel von Kisten kann aufgeteilt sein in mehrere Zielorte. Siehe Beispiele in Fotos. z.B. 22 Kisten auf drei Stapeln an 6 Zielorte.
- Art und Anzahl Gebinde (vorerst eingeschränkt auf folgende)
- Tasche (Grösse analog Papiersack)
- IFCO Kiste
- Optional: Inhalt der Ware (Bedarf an Kühlung)
- Kühlung ja/nein
Project Report (PDF)
Swiss AI Weeks Hackathon App
Setup
Server Setup
- Installiere die benötigten Python-Pakete:
cd apis
pip install -r requirements.txt
- Starte den Flask-Server:
cd apis
python flask_app.py
Der Server läuft dann unter http://localhost:8080
Flutter App Setup
- Installiere die Flutter-Abhängigkeiten:
cd hackathon_application
flutter pub get
- Starte die Flutter-App:
flutter run
Kommunikation zwischen App und Server
Die App sendet Chatnachrichten an den Server über den /chat Endpunkt. Der Server empfängt diese Nachrichten und antwortet darauf.
Wenn der Server nicht erreichbar ist, verwendet die App einen lokalen Fallback-Mechanismus.
API-Endpunkte
/chat- POST-Anfrage für Chatnachrichten/test_apertus- Test-Endpunkt für Apertus/get_route/<start>/<end>- Routenberechnung zwischen Start- und Endpunkt
Wichtige Dateien
hackathon_application/lib/providers/chat_provider.dart- Logik für den Chathackathon_application/lib/widgets/message_input.dart- UI für die Nachrichteneingabeapis/flask_app.py- Flask-Server mit API-Endpunkten
Measure footprint of open LLMs
Benchmark Apertus, compare with other models, and find strategies for efficient prompting.
The challenge is to measure and improve the environmental impact of the Swiss Large Language Model (Apertus, from the Swiss AI Initiative) and compare it with other models. Participants should design methods to quantify energy consumption, carbon emissions, and resource use during inference. In addition to transparent measurement frameworks or dashboards, solutions should propose concrete prompting strategies for impact reduction. The goal is to enable Switzerland to lead in sustainable AI by combining rigorous evaluation with actionable improvements.
Header photo: CSCS - Swiss National Supercomputing Centre
Purpose
The project aims to measure and improve the environmental impact of Large Language Models. It will create transparent benchmark and metrics as well as practical strategies to quantify and reduce energy use, carbon emissions, and resource consumption for inference. The goal is to enable sustainable AI that aligns with Switzerland’s leadership in responsible technology.
Inputs
A few initiatives (e.g. AI EnergyScore, MLCO2) have proposed frameworks for tracking carbon and energy usage, but these are not yet widely adopted or standardized. Based on one of these, we may try to:
- Develop measurement methods for the Swiss LLM’s energy and carbon footprint across its lifecycle.
- Explore prompting strategies for reducing impact
- Compare the energy consumption and the prompting strategies with other LLMs
- Document best practices and propose guidelines for sustainable Swiss AI.
Access to open source LLMs and underlying infrastructure is required to log compute usage, energy consumption, and hardware efficiency. We will provide a test machine (12GB VRAM 32GB RAM) on location, and remote access to a Mac Studio (192GB Unified Memory) for measurements.
Some technical information on the new Swiss LLM can be found here:
https://swissai.dribdat.cc/project/40
The following resources may be of use:
- https://ss64.com/mac/powermetrics.html
- https://codecarbon.io/
- https://huggingface.co/AIEnergyScore/spaces
- https://app.electricitymaps.com/
- https://mlco2.github.io/impact/
- https://ml.energy/zeus/
Papers of note:
- Green Prompting
- Evaluating the Energy–Performance Trade-Offs of Quantized LLM Agents (Weber et al 2025)
- Large Language Model Supply Chain: A Research Agenda (Wang et al 2025)
- Characterizing the Carbon Impact of LLM Inference (Lim et al 2024)
- Towards Greener LLMs: Bringing Energy-Efficiency to the Forefront of LLM Inference (Stojkovic et al 2024)
- LLMCarbon: Modeling the end-to-end Carbon Footprint of Large Language Models (Faiz et al 2023)
- MLPerf Inference Benchmark (Reddi et al 2020)

Comparison chart by Sourabh Mehta - ADaSci 2024
As outputs, the project will deliver measurements, guidelines for measuring and prompting techniques for reducing AI impact. It directly promotes open science, climate consciousness, and responsible AI. The outcomes can catalyze a larger initiative on sustainable foundation models in Switzerland, influencing both public policy and industry adoption.
Most foundation models today are evaluated primarily on accuracy, scale, and downstream performance. Environmental impact is often reported inconsistently or not at all. Large-scale LLMs typically lack region-specific sustainability benchmarks or actionable improvement strategies, so efforts to crowdsource such results will be valuable to the community.
The activities align with the Swiss AI Initiative’s goals of advancing responsible and trustworthy AI. By focusing on Switzerland’s energy mix and regulatory context, the project addresses local sustainability priorities while producing globally relevant methods. It strengthens Switzerland’s role as a leader in sustainable and ethical AI across Europe and beyond.
Compliance
Environmental impact measurement and mitigation align with Swiss and European climate targets, responsible AI guidelines, and open science principles. Data used will be technical (compute and energy metrics), avoiding personal or sensitive information.
Illustration by Nhor CC BY 3.0
Results
The goal of the project was to
- measure the energy consumption of inference on Apertus
- understand the influence of prompt and response on the energy consumption
- Bonus: compare to llama
Our measuring infrastructure consisted of Mac Studio with remote access.

We used the powermetrics tool with Begasoft BrandBot
Experiments
- Experiment 1: Prompt/Response length
- We tested different prompt and response lengths.
- Ex: Short-Long: Explain photosynthesis in detail.
- Experiment 2: Different subjects
- Experiment 3: Compare with Llama
- Experiment 4: Different languages
Learnings
We failed successfully on:
- getting a stable setup ❌
- excluding overhead ❌
- proper energy calculations ❌
- getting 2nd system to run ❌
- do physical measurements ❌
- change measurement method ❌
- automate everything ❌
- doing proper statistics ❌
We succeeded successfully on:
- measure idle consumption ✅
- measure different prompts ✅
- Integrated a new team member ✅
- learn a lot ✅
- having fun! ✅
Results
Measuring is hard!
Prompt size:
- long answers dominate the energy use
- long prompts have some influence
Different types of prompts: Basic knowledge, Chemistry, Geography, Math does not seem to influence the energy consumption (other than the length of the response)
Different languages: apart from the length, the language seems to have some influence (portugese: +20%)
Different models: inconclusive but similar
Reports
Thanks to all!
Energy Footprint Analysis of Open LLMs
This repository contains the results and methodology from the swissAI Hackathon challenge "Measure footprint of open LLMs".
🔗 Challenge Details: https://swissai.dribdat.cc/project/44
Team Members
- Agustín Herrerapicazo - agustin.it@proton.me
- Luis Barros - luisantoniio1998@gmail.com
- Stefan Aeschbacher - stefan@aeschbacher.ch
Project Overview
This project investigates the energy consumption patterns of the Apertus language model through controlled experiments measuring various aspects of prompting behavior.
Goals
- Primary: Understand the energy consumption characteristics of Apertus
- Secondary: Analyze energy impact across different prompting dimensions:
- Prompt length
- Response length
- Language of the prompt
- Subject matter of the prompt
- Optional: Compare Apertus performance with Llama 7B
Limitations
⚠️ Important: Apertus is in early development stages. Quality assessments would be premature and unfair at this time.
Infrastructure
Systems Used
-
Mac Studio (Primary)
- Remote access capability
- Physical measurement limitations due to remote setup
- Used for all experimental measurements
-
Shuttle with 8GB Nvidia GPU (Available but unused)
- Not utilized in final experiments
Measurement Validation
Initial testing revealed a 3x-4x discrepancy between powermetrics readings and physical measurements on the Mac Studio. Due to time constraints, this variance was noted but not fully investigated.
Measurement Tools & Scripts
Energy Measurement Script (measure.sh)
Custom bash script that orchestrates energy measurement using powermetrics:
Features:
- Real-time power monitoring with 100ms sampling intervals
- CSV output with structured data format
- Live progress display during measurement
- Automatic calculation of cumulative energy consumption
- Statistical analysis (min/max/average power, standard deviation)
Usage:
./measure.sh <duration_in_seconds> [test_name]
./measure.sh 60 "SS_math_test"
Output Format:
sample,elapsed_time,power_mw,cumulative_energy_j,test_name
1,0.10,380.00,0.038000,test_short_short
2,0.20,318.00,0.069800,test_short_short
Efficiency Analysis (quick_efficiency.py)
Python script for calculating token-to-energy efficiency metrics:
Key Metrics:
- Tokens per Joule (efficiency rating)
- Joules per Token (energy cost)
- Tokens per Second (processing speed)
- Energy efficiency rating system (⭐⭐⭐ Excellent > 1000 tokens/J)
Usage:
python3 quick_efficiency.py data.csv "model output text"
Data Visualization (test.py)
Comprehensive analysis and visualization tool:
Capabilities:
- Multi-file comparison analysis
- Power consumption profiles over time
- Statistical analysis with error bars
- Efficiency comparison charts
- Automated plot generation
Features:
- Single test detailed analysis
- Multi-test comparative analysis
- Normalized time comparisons
- Energy consumption trends
Powermetrics Integration
- Platform: Mac Studio
- Command:
powermetrics --samplers cpu_power -i 100 -n <duration> - Sampling Rate: 50ms effective (100ms configured with processing overhead)
- Metrics: Combined CPU/GPU power consumption in milliwatts
Yocto-Watt
- Type: Physical energy consumption device
- Usage: Baseline understanding of machine behavior
- Link: https://www.yoctopuce.com/EN/products/usb-electrical-sensors/yocto-watt
Experimental Setup
Standard Configuration
- Sampling Rate: 50ms intervals
- Powermetrics Command:
powermetrics --samplers cpu_power -i 100 -n "$DURATION"
Baseline Measurements
- Idle Consumption: 10 runs × 30 seconds each
- Observation: Irregular consumption peaks during idle state
- Impact: Background processes affected measurements but were accepted due to time constraints
Experiments & Results
1. Prompt Length Impact
Test Files: test_short_short, test_short_long, test_long_short, test_long_long
Tested all permutations of prompt and response length combinations to isolate energy consumption factors.
Methodology:
- Short prompts: ~10-20 words
- Long prompts: ~100+ words
- Short responses: ~10-50 tokens
- Long responses: ~200+ tokens
- Duration: ~260 seconds per test
Key Finding: Response length showed stronger correlation with energy consumption than prompt length.
2. Subject Matter Analysis
Test Files: test_short_topic_1 through test_short_topic_10
Evaluated energy consumption across different domains with consistent short prompt/short response format:
- Basic Knowledge
- Geography
- Chemistry
- Mathematics
- History
- Science
- Literature
- Technology
Methodology:
- 10 different subject prompts
- Consistent response length target
- ~270 seconds per test
- Statistical analysis across topics
Result: Subject matter showed minimal impact on energy consumption. Response length remained the primary factor. Average energy consumption varied by less than 5% across different topics.
3. Language Comparison
Test Files: test_short_language_1 through test_short_language_4
Tested four languages with controlled response lengths:
- German (
test_short_language_1) - Spanish (
test_short_language_2) - Portuguese (
test_short_language_3) - English (
test_short_language_4)
Methodology:
- Identical semantic prompts translated to each language
- Target response length controlled
- ~290 seconds per test
- Power consumption analysis
Notable Finding: Portuguese consumed approximately 20% more energy for similar response lengths, warranting further investigation. This could indicate tokenization differences or model efficiency variations across languages.
4. Apertus vs Llama 7B Comparison
Test Files: test_short_llm_fight_1 through test_short_llm_fight_4
Limited comparison between models with controlled prompt/response scenarios.
Methodology:
- Identical prompts for both models
- Short prompt, short response format
- 4 comparative test runs
- ~300 seconds per test
Result: No clear energy consumption trend identified. Both models showed similar energy usage patterns, with Apertus consuming approximately 50J more in comparable scenarios. More extensive testing needed for statistical significance.
5. Baseline Measurements
Test Files: idletest_*, test10 through test20
Idle Consumption Study:
- 10 runs of 30-second idle measurements
- Mac Studio background processes created measurement variance
- Standard deviation: ~15-20% of mean idle power
- Average idle power: ~250-300mW
Measurement Stability:
- 20 repeated measurements under identical conditions
- Assessed measurement reproducibility
- Identified systematic measurement overhead from powermetrics
Key Findings
- Response Length Correlation: Strong positive correlation between response length and energy consumption
- Prompt Length Impact: Minimal influence on overall energy usage
- Language Variance: Portuguese showed unexpected 20% higher consumption
- Model Comparison: Apertus and Llama 7B perform similarly in energy usage
Limitations & Future Work
Identified Issues
- System Stability: Mac Studio showed high idle consumption variance
- Measurement Overhead: Powermetrics introduces CPU load and timing discrepancies (~20ms vs 100ms target)
- Physical vs Digital: 3x-4x gap between powermetrics and physical measurements needs quantification
- Sample Size: Limited runs per experiment due to time constraints
Recommendations
- Investigate and eliminate idle consumption variance sources
- Quantify powermetrics measurement overhead impact
- Establish correlation between digital metrics and physical power consumption
- Increase sample sizes for statistical significance
Technical Implementation
Data Collection Pipeline
- Measurement Script (
measure.sh): Orchestrates powermetrics data collection - Real-time Processing: AWK script processes powermetrics output stream
- Data Storage: Structured CSV format with timestamp synchronization
- Analysis Tools: Python scripts for statistical analysis and visualization
File Structure
├── measure.sh # Main measurement orchestration script
├── quick_efficiency.py # Token efficiency analysis tool
├── test.py # Data visualization and comparison
├── data/ # Experimental results (42 CSV files)
│ ├── idletest_* # Baseline idle measurements
│ ├── test_short_short # Short prompt/short response
│ ├── test_long_long # Long prompt/long response
│ ├── test_short_topic_* # Subject matter experiments
│ ├── test_short_language_* # Language comparison tests
│ └── test_short_llm_fight_* # Model comparison tests
└── energy_analysis.png # Generated visualization
Data Format Specification
Each measurement produces timestamped CSV files with the following schema:
sample,elapsed_time,power_mw,cumulative_energy_j,test_name
- sample: Sequential measurement number
- elapsed_time: Time elapsed since measurement start (seconds)
- power_mw: Instantaneous power consumption (milliwatts)
- cumulative_energy_j: Running total energy consumption (joules)
- test_name: Experiment identifier for batch processing
Statistical Analysis Methods
- Central Tendency: Mean, median power consumption calculation
- Variability: Standard deviation analysis for measurement stability
- Energy Integration: Cumulative energy calculation using trapezoidal rule
- Comparative Analysis: Multi-test statistical comparison with confidence intervals
Reproducibility
Dependencies
- macOS: powermetrics utility (built-in)
- Python 3.x: pandas, matplotlib for analysis scripts
- Hardware: Mac Studio (M1/M2) or compatible Apple Silicon system
Running the Experiments
# 1. Make measurement script executable
chmod +x measure.sh
# 2. Run energy measurement (requires sudo for powermetrics)
./measure.sh 300 "my_experiment"
# 3. Analyze results
python3 quick_efficiency.py my_experiment_*.csv "model output text"
# 4. Generate visualizations
python3 test.py data/*.csv
Dataset Summary
Total Measurements: 42 experimental runs Data Points: ~12,000 individual power measurements Test Categories:
- Baseline idle: 12 runs
- Prompt length: 4 systematic tests
- Subject matter: 10 domain-specific tests
- Language comparison: 4 language tests
- Model comparison: 4 head-to-head tests
- Stability assessment: 20 repeated measurements
Conclusion
This proof-of-concept demonstrates feasible methodologies for LLM energy consumption measurement and provides initial insights into consumption patterns. The comprehensive dataset of 42 experimental runs with over 12,000 data points establishes a foundation for more rigorous future analysis.
Primary Insights:
- Response Length Dominance: Strong positive correlation between token output and energy consumption
- Prompt Length Independence: Minimal energy impact from input prompt length variations
- Language Efficiency Variance: Notable 20% difference between languages (Portuguese anomaly)
- Model Parity: Apertus and Llama 7B show similar energy profiles within measurement uncertainty
- Measurement Methodology: Established reproducible framework for LLM energy analysis
Technical Contributions:
- Automated measurement pipeline with real-time analysis
- Structured dataset with comprehensive experimental coverage
- Statistical analysis framework for energy efficiency assessment
- Open-source toolset for reproducible LLM energy research
Future Work: Quantify powermetrics calibration, expand language coverage, increase statistical sample sizes, and investigate tokenization impacts on energy consumption patterns.
This work represents exploratory research conducted during a hackathon timeframe and should be considered preliminary findings rather than conclusive scientific results. All code and data are available for reproduction and extension.
Tibetan Chatbot
To help learn a new language using chat interfaces, let's use Apertus to build a RAG based on a dataset of linguistic references.
The aim is to develop a user-friendly chat interface that facilitates learning the Tibetan language. By leveraging Apertus, the Swiss LLM, and building a Retrieval-Augmented Generation (RAG) system, we have created an interactive tool that enhances language acquisition through engaging conversations.
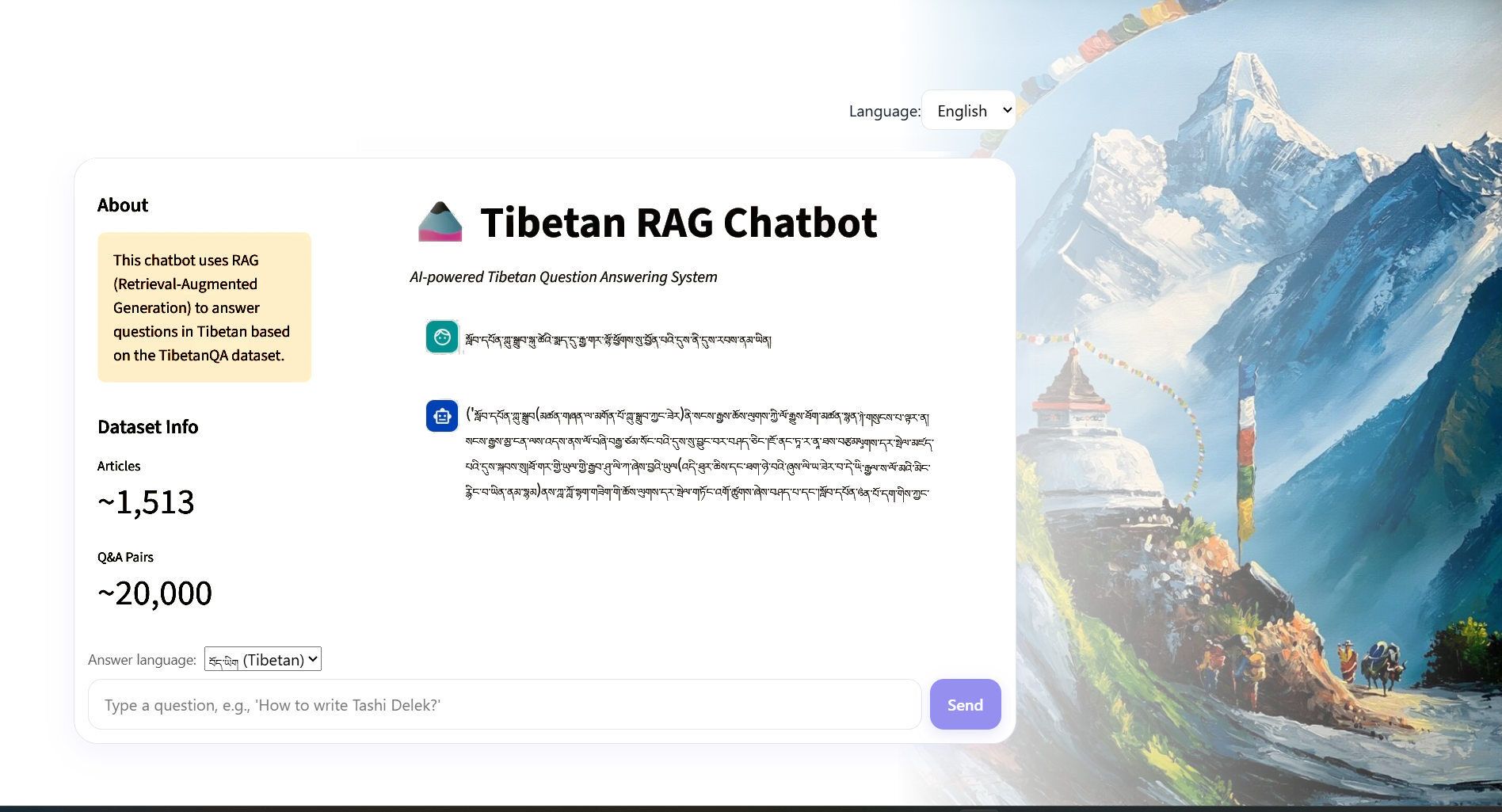
Screenshot of our prototype UI, running a chat interface with a question and answer in Tibetan.
Challenge
Current practices in language learning often rely on static resources and lack interactive elements. Foundation models in this area typically focus on translation and basic grammar, but there is a gap in creating dynamic, conversational learning experiences. The state-of-the-art involves using large language models for text generation, but integrating these with specific language datasets and creating a user-friendly interface remains a frontier.
Activities in this project may include:
- Gather and preprocess Tibetan language datasets, ensuring they are clean and structured for model training.
- Train the Swiss LLM on the Tibetan dataset and integrate it with a RAG system to enhance conversational capabilities.
- Develop a prototype of the chat interface, focusing on user experience and interaction design.
- Conduct user testing to gather feedback and iterate on the prototype, ensuring it meets the learning needs of users.
- Document the process, outcomes, and create a presentation for the hackathon.
Resources
- Datasets: Tibetan language corpora, including textbooks, dictionaries, and conversational scripts.
- AI Models: Swiss LLM for language generation and RAG for enhancing conversational accuracy.
- Infrastructure: Cloud-based computing resources for model training and deployment.
- Tools: Programming languages (Python), frameworks (TensorFlow, PyTorch), and design tools (Figma, Adobe XD).
Team
I am knowledgeable in Tibetan language structure and existing learning apps, and am looking to build a team to include people:
- Experienced in handling and preprocessing language datasets.
- Interested in training and integrating large language models for educaiton.
- A designer who could help us in prototyping an intuitive and engaging user interface.
- Someone to help manage the team, and ensure a smooth collaboration.
Outputs and Outcomes
This project will promote open science by making the chatbot interface and underlying datasets publicly available. It will also foster responsible AI practices by ensuring fairness and inclusivity in language learning. The outcomes will catalyze a larger project focused on enhancing language learning experiences through AI, aligning with the goals of the Swiss AI Initiative.
Geographic Relevance
The Tibetan community in Switzerland began forming in the early 1960s and is now the largest Tibetan diaspora group in Europe. [Wikipedia]. The project aligns with the goals of the Swiss AI Initiative by leveraging Swiss AI models and promoting language learning. It has strategic importance for Swiss society by providing a tool for cultural and linguistic preservation. The impact extends to Europe and the world, offering a unique approach to language learning that can be adapted for other languages and cultures.
Ethics and Regulatory Compliance
Ethical considerations include ensuring the chatbot provides accurate and respectful language learning experiences. Compliance with legal and regulatory guidelines will be maintained by adhering to data privacy laws and ensuring the chatbot does not perpetuate biases or misinformation.
🅰️ℹ️ Generated with help of MISTRAL24B

🖼️ Part of a manuscript copy of a Vijaya in Tibetan - Public Domain
{kind=link}