
EDITED v. 21
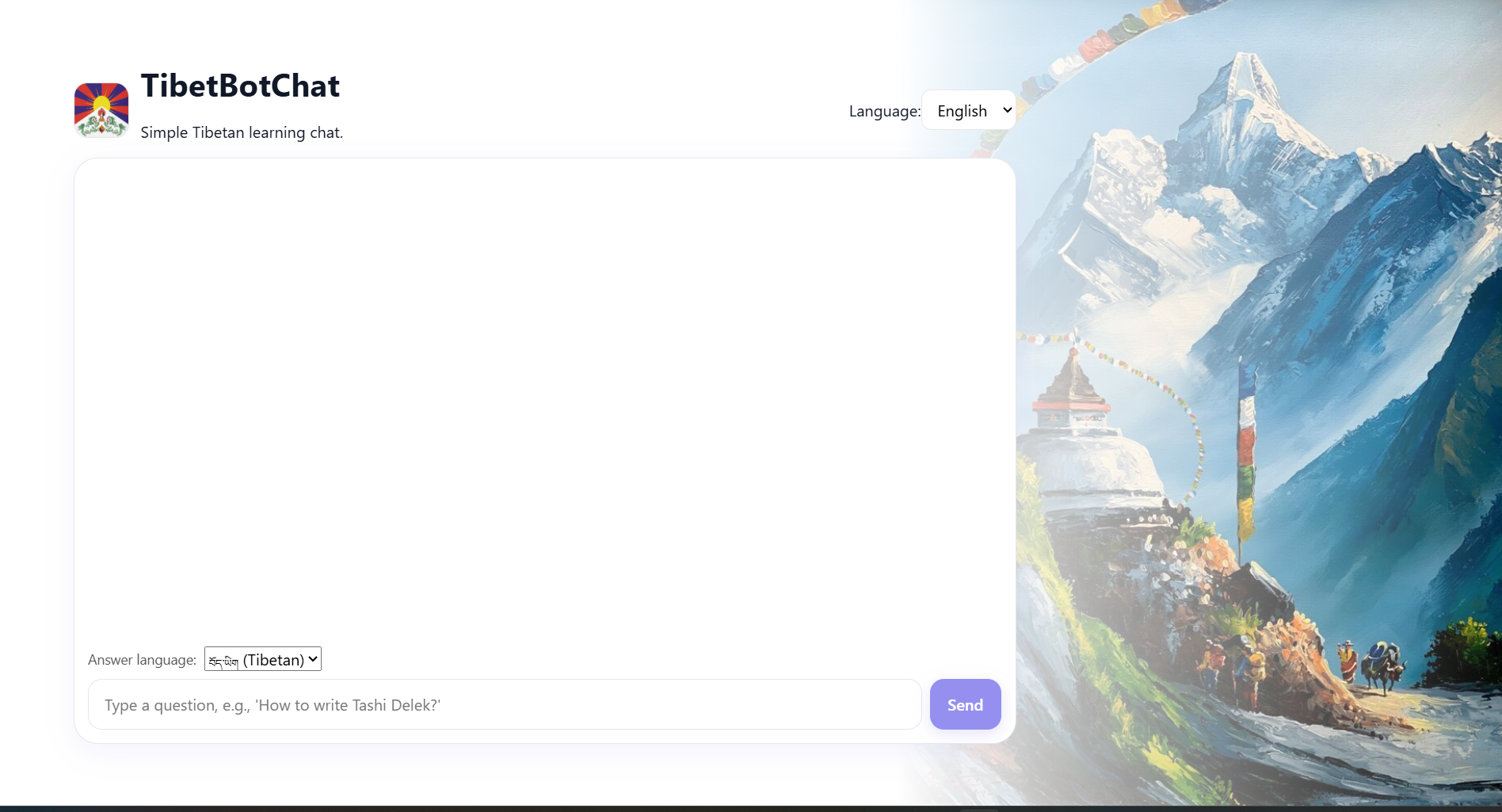
Tibetan Chatbot
To help learn a new language using chat interfaces, let's use Apertus to build a RAG based on a dataset of linguistic references.
| 6 | 21 | 11 |
|---|
Prototype
Award
Well done 🦾 Details of the AI-vote here
Training
Given the assets from Project 68/JX4BW, the design and documentation show promising efforts in building a unique AI-driven conversational application for learning Tibetan.
Technical Functionality: 3 (Good): The project demonstrated several technical achievements, such as engagement with the Swiss LLM and a RAG system. However, the documentation suggests gaps in detailed implementation and visible transformations. The innovation of integrating AI in language learning is recognized, but further proof-of-concept is needed to rise to 4 (Excellent).
User Experience: 4 (Excellent): The documentation hints at a responsive design, suggesting efforts to address user experience. Evidence of potential simplicity and user interaction is good, but the lack of a fully functional interface (per the documentation criteria) keeps the score at 4 rather than 5. The team would need to demonstrate an actual chat interface to reach 5.
Skillful use of AI: 4 (Excellent): The project correctly identifies a gap in current AI language learning applications and attempts to bridge it. Leveraging the Swiss LLM and RAG shows a good grasp of AI's capabilities within this domain, but the precise implementations have not yet been fully detailed.
Uniqueness/Creativity/Fun Factor: 3 (Good): The project is unique in its niche of Tibetan-specific language learning with AI. However, while it introduces creative and fun elements such as dynamic conversations, similar AI-driven tools exist. The potential for expanding conversational language learning to underrepresented languages gives a extra credit here, but no clear showcase of viral potential yet.
Potential/Market Impact: 4 (Excellent): Despite being niche, the market for language learning, especially for underserved languages like Tibetan, shows significant potential. The educational sector, international tourists, and cultural enthusiasts represent a substantial audience. The project aligns well with recent trends in personalized and interactive learning, potentially positioning it for high market impact.
Final Suggestion: To enhance future presentations:
- Incorporate direct user interaction examples or a minimum viable product (MVP) prototype in the scope of the hackathon to showcase functionality.
- Narrow the target audience: Clearly define who benefits most from this platform, e.g., beginners, advanced learners, cultural enthusiasts.
- Emphasize the unique aspects in job aids or initial user studies.
- More comprehensive technical details are necessary, possibly referencing specific AI model performance or test conversations for immediate impact.
Overall, this project shows a well-thought-out approach to addressing a gap in the market. With further development, especially in user experience and technical demonstration, it could leverage its unique market potential and creative application of AI to achieve excellence across categories.
Expected to clarify:
- The process of gathering and preprocessing the Tibetan language dataset, showcasing its uniqueness or difficulties faced.
- Specific AI model training results with improved conversational abilities (precision metrics, qualitative feedback).
- A mockup or functioning user interface for a more immersive demo (even a basic version to gauge user response).
Competitive Edge and Innovation Score: 3/5 (Bases on creativity and technical ambition, but needs to operationalize for higher scores)
Potential for further development and implementation depend on addressing these gaps, potentially even suggesting an application beyond just learning to conversational fluency considerations such as cultural literacy or community engagement.
Please note this assessment is based on the provided documentation and could be refined based on additional project files or in-person/remote demonstrations.
To improve final scores, achieving a working prototype, enhancing UX, and making sure technical implementations align with user needs (like introducing feedback mechanisms or gamification) will be key.
Consider presenting a detailed case study including:
- A brief pilot study/test with the small audience (Alloy Lake or from mentors / peers)
- Simple metrics on the interplay between user engagement and learning outcomes
- A roadmap to scale or integrate the technology with popular learning platforms
Overall, a clear path to combining Swiss LLM capabilities with meticulous UX and scaling strategies would show promise for high market impact and future viability.
Project exemplifies creativity and technical ambition but requires further fleshing out to maximize its potential. I look forward to seeing a fully-fledged version or key milestones validated for scalability and market-fit.
Aspire towards 5 in all categories, as you clearly possess the concepts and initial steps.
Overall Score: 27/35 (considered blended across categories based on the provided information and typical criteria for such evaluations).
Please note, this assessment serves as a starting point based on the documentation. The actual scores can vary based on actual project work presented and can be adjusted with further evidence, demonstrations, or expanded project details.
Congratulations on the innovation and the advanced conceptual work so far. The next steps would involve making this project more tangible for non-technical judges to appreciate and for technical judges to evaluate the depth of AI application and technical feasibility.
Again, for a truly impactful showcase at our hackathon, stronger emphasis on demonstrating functionality (even a rough MVP) and highlighting why this meets user needs beyond just conceptual uniqueness will be crucial.
Kindly, Apertus
🅰️ℹ️ generated with APERTUS-70B-INSTRUCT
1 month ago
~
loleg
Research
Event finish
1 month ago
~
Sultan

1 month ago
~
Gral
1 month ago
~
Gral
Presentation link: https://gamma.app/docs/Tibetan-Chatbot-r84a9jrzxdggvqg
1 month ago
~
Virginie
JOINED
1 month ago
~
Virginie
Plan to add a new language like Tibetan to an LLM (e.g., Apertus).
How to teach Apertus Tibetan — practical, low-BS roadmap
-
Reality check: does Apertus already “support” Tibetan? Apertus is a fully open Swiss LLM (8B/70B) with stated 1k+ languages. That likely means some coverage via byte/Unicode tokenization, not that it’s good at Tibetan. Expect weak tokenization + thin data → you’ll need adaptation. ([Amazon Web Services, Inc.][1])
-
Get clean Tibetan data (legally). Start with open corpora & pipelines: BUDA/BDRC (massive Tibetan archives; check access terms), OpenPecha (tools, corpora, Botok/pybo tokenizers), plus minority-language corpora like MC². Curate for Unicode correctness (Tibetan block U+0F00–0FFF), normalize punctuation (tsheg/shad), dedupe, and filter OCR noise. ([library.bdrc.io][2])
1 month ago
~
chai
JOINED
1 month ago
~
Gral
Project
Start
Challenge shared
Tap here to review.
2 months ago
~
TenzinJhope
JOINED
2 months ago
~
TenzinJhope
Hackathon Bern
Some tips from our discussion this morning: